
What Is Statistical Arbitrage?
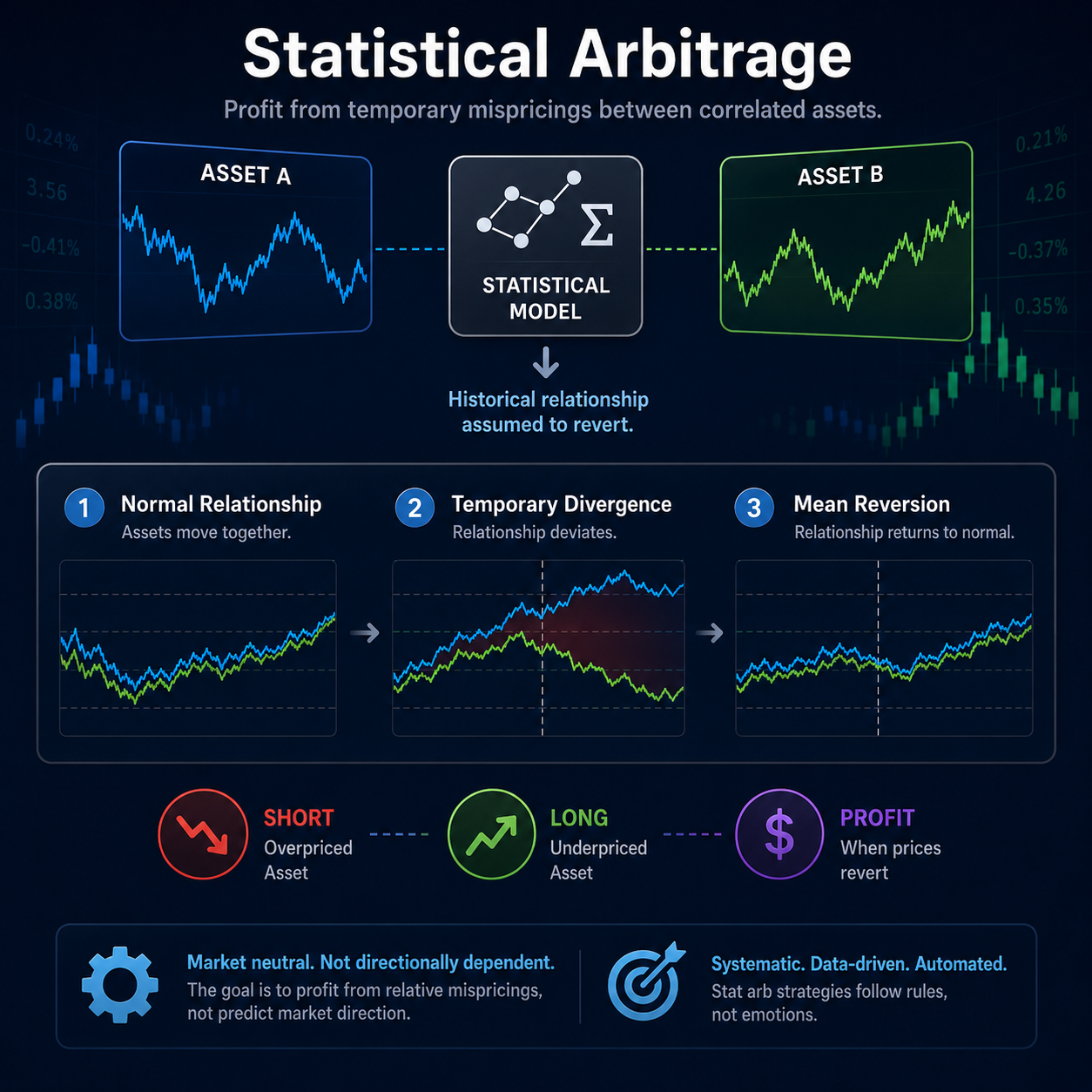
Statistical arbitrage, often called “Stat Arb,” is a quantitative trading strategy that attempts to profit from temporary pricing inefficiencies between correlated financial assets. Unlike traditional investing, which may rely on company fundamentals or discretionary decision-making, statistical arbitrage is driven by mathematical models, probability, and historical market behavior.
The foundation of statistical arbitrage is the assumption that certain securities maintain stable statistical relationships over time. When those relationships temporarily diverge, quantitative traders attempt to profit from the expected reversion back to normal.
Stat arb strategies are widely used by:
- Quant hedge funds
- Proprietary trading firms
- High-frequency trading firms
- Institutional asset managers
Modern statistical arbitrage strategies rely heavily on:
- Mean reversion models
- Cointegration analysis
- Factor models
- Machine learning systems
- Z-score signal generation
Many of the world’s most successful quantitative firms, including Renaissance Technologies and Two Sigma, use forms of statistical arbitrage within broader systematic quant trading strategies.
How Statistical Arbitrage Works
Statistical arbitrage strategies generally follow a structured process:
- Identify correlated or cointegrated assets
- Measure deviations in their relationship
- Generate trade signals using statistical thresholds
- Execute trades automatically
- Close positions once prices revert
The goal is not to predict market direction but to profit from relative mispricing between securities.
Because most stat arb systems are automated, they are closely tied to algorithmic trading infrastructure and execution systems.
Pair Trading Fundamentals
One of the most common forms of statistical arbitrage is pair trading.
In pair trading, traders identify two securities that historically move together. These are usually companies in the same industry or assets influenced by similar macroeconomic conditions.
Examples include:
- Coca-Cola and Pepsi
- Visa and Mastercard
- ExxonMobil and Chevron
If the relationship temporarily diverges, traders assume the spread will eventually revert to its historical average.
For example:
- Coca-Cola rises sharply
- Pepsi remains flat
- The spread between them widens abnormally
A statistical arbitrage trader may:
- Short Coca-Cola
- Long Pepsi
If the historical relationship normalizes, the trader profits regardless of whether the broader market rises or falls.
This market-neutral structure is one reason statistical arbitrage became extremely popular among hedge funds and broader quantitative trading firms.
Mean Reversion Logic
Mean reversion is the core principle behind most statistical arbitrage systems.
The idea is simple:
Prices and spreads tend to fluctuate around long-term averages. Extreme deviations are statistically likely to revert over time.
This concept is explored in greater detail in mean reversion trading, which forms the foundation of many quantitative models.
Z-Score Signal Generation
Z-scores are commonly used to trigger trades.
Typical signal logic:
- Enter short spread trade when Z-score > 2
- Enter long spread trade when Z-score < -2
- Exit trade when Z-score returns toward 0
This creates a systematic framework that removes emotional decision-making from trading.
For example:
- If Coca-Cola significantly outperforms Pepsi beyond historical norms, the z-score increases
- The system identifies the divergence as statistically abnormal
- A reversion trade is executed automatically
Because the process is rules-based, statistical arbitrage is highly compatible with modern algorithmic trading systems.

Types of Statistical Arbitrage Strategies
Statistical arbitrage has evolved far beyond simple pair trading. Modern quant firms use sophisticated multi-factor and machine learning systems capable of analyzing thousands of securities simultaneously.
These strategies are part of a broader ecosystem of advanced quant trading strategies used by hedge funds and institutional investors.
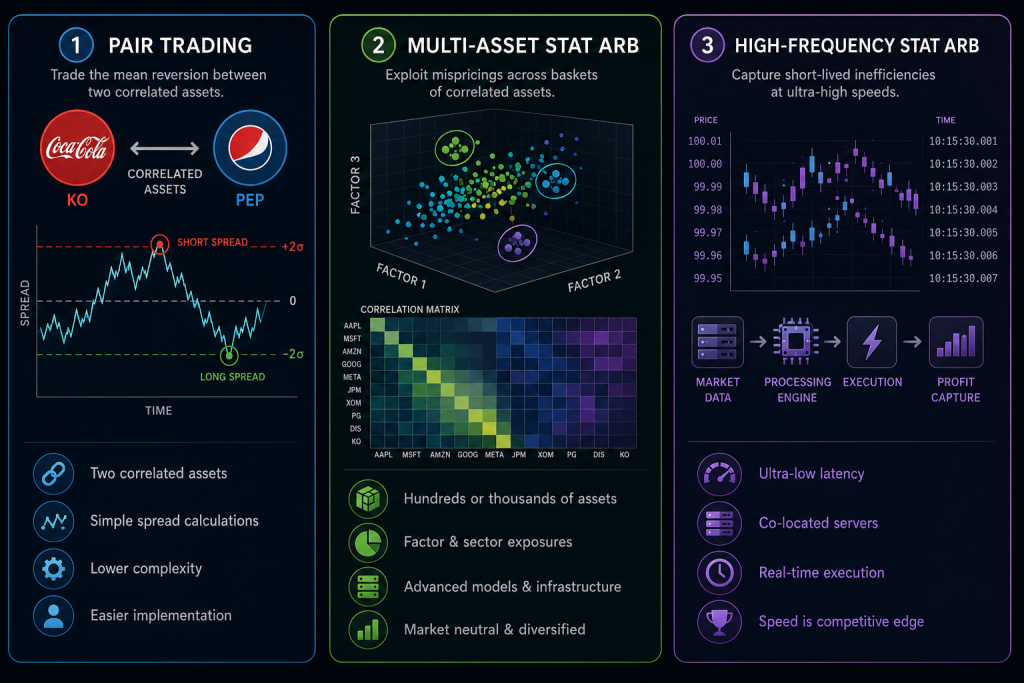
Pair Trading
Pair trading is the classic form of statistical arbitrage.
Characteristics include:
- Two correlated assets
- Simple spread calculations
- Lower complexity
- Easier implementation for retail traders
Retail quantitative traders often begin with pair trading because it requires:
- Less computing power
- Simpler models
- Smaller datasets
Despite its simplicity, pair trading remains widely used across institutional finance and is often compared with other systematic methods in momentum vs mean reversion discussions.
Multi-Asset Statistical Arbitrage
More advanced statistical arbitrage systems analyze baskets of assets rather than individual pairs.
These models may incorporate:
- Factor exposures
- Sector relationships
- Volatility adjustments
- Correlation matrices
Instead of analyzing one relationship, multi-asset systems search for hundreds or thousands of small inefficiencies simultaneously.
This approach is commonly used by:
- Quant hedge funds
- Institutional systematic funds
- Market-neutral portfolios
Multi-asset statistical arbitrage typically requires:
- Large datasets
- Advanced infrastructure
- Significant computational power
These systems are a major part of modern quantitative trading firms and systematic hedge funds.
High-Frequency Statistical Arbitrage
High-frequency stat arb focuses on very short-term inefficiencies that may last only milliseconds or seconds.
These systems rely on:
- Ultra-low-latency infrastructure
- Co-located servers
- Real-time execution systems
High-frequency statistical arbitrage firms compete on speed because even microsecond delays can eliminate profitability.
This area overlaps heavily with advanced algorithmic trading and low-latency infrastructure engineering.
This area of quantitative finance is dominated by:
- Citadel Securities
- Jane Street
- Virtu Financial
For most retail traders, high-frequency stat arb is not realistically accessible due to infrastructure costs.
Tools & Technology Used
Modern statistical arbitrage is deeply technology-driven. Success depends not only on strategy design but also on data quality, execution speed, and computational efficiency.
Programming Languages
Python is the most popular language in modern quantitative finance because of its strong data science ecosystem.
Common Python libraries include:
- Pandas
- NumPy
- SciPy
- Statsmodels
- scikit-learn
R is also widely used for:
- Statistical analysis
- Academic research
- Time-series modeling
Institutional trading firms may additionally use:
- C++ for ultra-low latency systems
- Java for execution infrastructure
If you want to build systems like these yourself, learning Python for quant trading is one of the best starting points.
Data Requirements
Statistical arbitrage strategies require large amounts of high-quality data.
Typical datasets include:
- Historical price data
- Tick-level market data
- Volume data
- Volatility data
- Corporate actions
Poor-quality data can severely damage model performance.
Institutional firms spend millions annually on:
- Proprietary market data
- Alternative datasets
- Real-time feeds
High-quality data infrastructure is one reason large quantitative trading firms maintain significant competitive advantages.
Execution Infrastructure
Execution quality is critical because statistical arbitrage often targets small inefficiencies.
Core infrastructure components include:
- Automated execution engines
- Risk management systems
- Order routing systems
- Latency optimization tools
As competition increases, execution efficiency becomes a major edge in modern algorithmic trading.
Risks of Statistical Arbitrage
Despite its mathematical sophistication, statistical arbitrage carries significant risks.
Model Breakdown
Models are based on historical relationships, but markets constantly evolve.
A strategy that worked historically may suddenly fail if:
- Market structure changes
- Volatility spikes
- Correlations shift
This is one reason diversified quant trading strategies are often preferred over single-model approaches.
Correlation Instability
Assets that historically moved together can permanently diverge.
For example:
- Industry disruption
- Regulatory changes
- Earnings shocks
This can break previously stable relationships. This challenge is frequently discussed when comparing momentum vs mean reversion systems.
Transaction Costs
Because statistical arbitrage often involves frequent trading, costs matter significantly.
These include:
- Commissions
- Slippage
- Bid-ask spreads
Small inefficiencies can disappear entirely after costs are included.
Liquidity Risk
In stressed markets, liquidity can evaporate quickly.
This can make it difficult to:
- Exit positions
- Maintain spreads
- Control losses
Liquidity crises have historically caused major losses for quantitative funds.
FAQ: Is Statistical Arbitrage Still Profitable?
Yes, statistical arbitrage is still profitable, but the industry has become far more competitive.
Modern success typically requires:
- Better datasets
- Faster execution systems
- More sophisticated models
- Strong infrastructure
Simple strategies that worked decades ago are now heavily crowded.
However, institutional firms continue generating returns using advanced quantitative trading strategies.
FAQ: Can Individuals Use Statistical Arbitrage?
Yes, retail traders can implement simplified forms of statistical arbitrage, especially pair trading strategies.
However, individuals face disadvantages including:
- Limited capital
- Slower execution
- Less access to premium data
- Higher transaction costs
Retail traders can still experiment using Python and publicly available market data, but competing directly with institutional firms is difficult.
Learning the foundations of Python for quant trading and algorithmic trading can help individual traders build basic stat arb systems over time.





